|
|
|
Models | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Natural and unnatural languagesI personally like naturalistic languages, so my constructed languages (conlangs) are full of irregularities, quirky lexical derivations, and interesting idioms. It’s easier, no doubt, to create a logical language, and desirable if you want to create an auxiliary interlanguage (auxlang), à la Esperanto. The danger here is a) creating a system so pristine, so abstract, that it’s also impossible to learn; or b) not noticing when you reproduce some illogicality present in the models you’re using. Ask me about the irregularities of Esperanto sometime. Non-Western (or at least non-English) modelsLooking at some non-Indo-European languages, such as Quechua (see my intro to Quechua here), Chinese, Turkish, Arabic, or Swahili, can be eye-opening. Learn other languages, if you can. If languages are difficult for you, just skim a grammar for nice ideas to steal. Bernard Comrie’s The World’s Major Languages contains meaty descriptions of fifty languages. Anatole Lyovin’s An Introduction to the Languages of the World readably surveys all the world’s language families, pointing out touristic highlights, and gives more detailed sketches of some important languages Comrie skips. If you don’t know another language well, you’re pretty much doomed to produce ciphers of English. Checking out grammars (or this Kit) can help you avoid duplicating English grammar, and give you some neat ideas to try out; but the real difficulty is in the lexicon. If all you know is English, you’ll tend to duplicate the structure and idioms of the English vocabulary. Below I’ll give you some hints on minimizing this problem.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Sounds | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
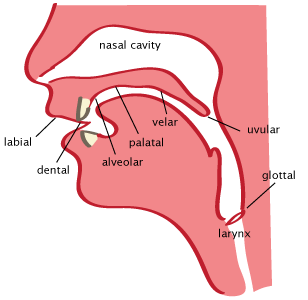
Non-linguists will often start with the alphabet and add a few apostrophes and diacritical marks. The results are likely to be something that looks too much like English, has many more sounds than necessary, and which even the author doesn’t know how to pronounce. You’ll get better results the more you know about phonetics (the study of the possible sounds of language) and phonology (how sounds are actually used in language). If you read just one book on linguistics... besides mine, I mean... make it J.C. Catford’s A Practical Introduction to Phonetics. Catford goes through the possible sounds systematically, with practical descriptions of how to produce each one even without having heard them. Don’t get too alarmed by the technical terms below. There’s a lot of them, but they’re all good to know, and the rest of the document isn’t as hard. Real linguists and their notationLanguage textbooks often describe sounds by comparison with English, offering recipes for producing unusual sounds. Linguists instead use the IPA (International Phonetic Alphabet), a set of symbols with precise meanings.I won’t rely heavily on the IPA here, as it’s kind of baffling till you’ve learned something about phonology. But I’ll introduce the symbols as we talk about each sound. To make it clear when I’m using an IPA symbol, I’ll print them like this: p. Many of them, like p, are what you’d expect from English. Types of consonantsConsonants are formed by obstructing the flow of air from the lungs. In linguistics, we don’t organize them alphabetically, but in a two-dimensional grid: place of articulation vs. closure.Place of articulationPlace of articulation describes where the obstruction occurs. By convention, we start at the lips and move inward. Compare the descriptions to the diagram, and make sure to pronounce the consonants to feel where they're produced.
If you need to distinguish dental from post-alveolar t, d in IPA, you can use t̪ d̪ for the dentals. Degree of closureConsonants also vary in how much they obstruct the airflow.
It often surprises English speakers that phonetically ch is just t + sh (tʃ). Similarly j is d + zh (dʒ). Confusingly, the IPA for our y is j. Think of the German j. More distinctionsVoicing is whether the vocal cords are vibrating or not. (If you’re not quite sure: when you hum, they’re vibrating; when you whisper, they’re not.) Voicing is the difference between f and v, t and d, k and g, sh and zh.Voiced and unvoiced consonants usually come in pairs, but not always. For instance, Spanish has s but not z; Arabic has b but not p. Voicing isn’t binary; rather, consonants vary in how soon the voicing starts— voicing onset time, VOT. English has fairly late VOT; French has early VOT. With nasal consonants, air travels through the nose as well as the mouth: m, n, ng (ŋ). The mouth does the exact same thing for b as for m; the difference is that the nasal passage is open for m (which also means that the sound can be prolonged). Stops may be released lightly or with a noticeable puff of air— aspiration. In English, we aspirate unvoiced stops at the beginning of a word (pot, tall, cow) but not after an s (spot, stall, scow). French and Spanish don’t have this initial aspiration. In Mandarin Chinese, Hindi, or Quechua, there are separate series of aspirated and non-aspirated stops: p pʰ. (As shown, the IPA is a superscript h.) Beijing doesn’t begin with a b but with an unaspirated p. Palatalized consonants are pronounced while raising the tongue toward the top of the mouth. That’s about the position for y, and a palatalized consonant may sound to English speakers as if there’s a y before or after it. In Russian and Gaelic, there are distinct series of palatalized and non-palatalized consonants. Palatalization is marked in IPA with a superscript j, as in nʲet, Russian нет. RhoticsRhotics, r-like sounds, come in several variants.
LateralsThere are also several laterals, l-like sounds, where the tongue is in position for a stop but space is left on the side for the air to get by.
The consonant gridLinguists prefer to arrange consonants in a grid. Here’s the grid for American English:
English th is really two sounds, the unvoiced θ of thick and the voiced ð of this. For the alveolar-palatal column I used the English spellings; sh zh are ʃ ʒ; ch j are tʃ dʒ; y is j. And ng is ŋ. At this point, if you’re given a name like voiced velar stop or unvoiced alveolar-palatal approximant, you should be able to figure out what it means. Inventing consonantsYou’ll notice that the grid of consonants for English has gaps in it. Does this mean you can invent new sounds by filling in the grid? Oh yes. Take the cell right under k g— the labels tell us that it’s for velar fricatives. The unvoiced version is x, fantasy writers’ beloved kh, as in German Bach. There is a voiced version gh ɣ, found in Greek. How about a labial affricate pf? German has one. It’s possible to make labial fricatives ɸ β too— not f as that involves the lower lip touching the teeth, but a lightly hissing fricative formed with just the lips. Japanese Fuji begins with ɸ; Spanish b, v in the middle of a word are pronounced β. Even more exciting is to add entire series of consonants using contrasts not used in English, such as palatalization or aspiration. Or remove a series English has. Cuzco Quechua, for instance, has three series of stops: aspirated, non-aspirated, and glottalized, but it doesn’t distinguish voiced and unvoiced consonants. The key to a naturalistic language, in fact, is to add (or subtract) entire dimensions. It’s conceivable that a language could have a single glottalized consonant, but more likely that it will have a series of them (along the points of articulation: p’ t’ k’). A language might have just two palatalized consonants (Spanish does: ll, ñ), but one that has a whole series of them is more typical. You can also add places of articulation. For instance, while English has three series of stops, Hindi has five (labial, dental, retroflex, alveolo-palatal, and velar. Retroflex consonants involve curling the tongue backwards a bit), and Arabic has six (bilabial, dental, ‘emphatic’ (don’t ask), velar, uvular, glottal). Some consonants are more common than others. For instance, virtually all languages have the simple stops p t k. Lass’s Phonology gives examples; see also David Crystal’s The Cambridge Encyclopedia of Language, p. 165. VowelsThe most important aspects of vowels are height and frontness. Height is how far the tongue is raised within the mouth; the mouth also tends to open wider as the tongue lowers, so lower vowels are also called open. The usual scale is high i u as in me moo, mid e o as in say so, and low a as in sock. (Pronounce these as in the examples... if you're wondering why we say A as ej, E as i and I as aj, it has to do with a sound change centuries ago called the Great Vowel Shift.) Many languages, including English, have four steps instead. Instead of mid there are two heights:
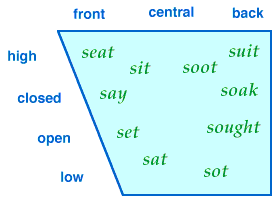
Frontness is how close the tongue is to the front of the mouth.
The vowel gridYou can arrange the vowels in a grid according to these two dimensions. The bottom of the grid is usually drawn shorter because there isn’t as much room for the tongue to maneuver as the mouth opens more. To get a feel for these distinctions, pronounce the words in the diagram, moving from top to bottom or side to side, and noting where your tongue is and how close it is to the roof of the mouth. The words shown may not match your own dialect. The important thing here is to understand what your tongue is doing as it makes front vs. back and high vs. low sounds. The ideal IPA vowels are as extreme as possible— e.g. i is as front and high as you can get it. Other vowel distinctionsVowels can vary along other dimensions as well. The lips can be rounded or not. It’s typical for front vowels like i e ɛ to be unrounded, and back vowels like u o ɔ to be rounded. Say moo and note how your lips are pursed— that’s rounding. Compare me, which should be unrounded. English doesn’t have front rounded vowels, but French and German do (Fr. u, oe; Ger. ü, ö). The IPA symbols are high y, closed ø, and open œ. To pronounce y, say i and round the lips as for u. The IPA symbols for back unrounded vowels are high ɯ, closed ɤ, open ʌ. For many English speakers the latter is the vowel in cut. Russian ы and Japanese u are both ɯ; to pronounce this, say u with lips relaxed. Vowels may constrast by length, as in Latin, Greek, Sanskrit, and Old English. Estonian has three degrees of length. A long vowel is simply pronounced longer. A long a is often transcribed ā, though the IPA is a:. Like consonants, vowels can be nasalized— pronounced with the nasal passage open. French, for instance, has four nasalized vowels œ̃ ɔ̃ ɛ̃ ɑ̃ as in un bon vin blanc. When two vowels are adjacent, they normally form a diphthong, as in English coy, cow, guy koj kaw gaj. The vowels are not really distinct; the position of the vocal organs glides smoothly from one position to the other. English tends to diphthongize its closed vowels— e.g. day, go are pronounced dej gow. In most languages you want to avoid this— e.g. French thé, tôt are a pure te to. Vowel systemsEnglish has a rather complicated vowel system:
Lax vowels are pronounced closer to the center of the vowel space— more like shwa— while tense vowels are pronounced closer to the periphery. Pronounce the words above (if you’re a native speaker) to get a feel for the contrast. Interesting simple systems include Quechua (three vowels, i u a) and Spanish (five: i e a o u). Simple vowel systems tend to spread out; a Quechua i, for instance, can sound like English pit, peat, or pet. Spanish e and o are open (as in pet, caught) in syllables that end in a consonant, closed (as in pate, pot) elsewhere. Again, for your conlang, don’t just add an exotic vowel or two; try to invent a vowel system, using the dimensions listed above. For instance, starting from the English system, you could bag the tense/lax distinction, add roundedness, and then collapse the front and back low vowels (there are often more high than low vowels). Phones, phonemes, and allophonesSounds is too vague for linguistics. And please don’t call them letters! The raw sounds people produce are called phones. (They’re actually messier than I’ve described, as phonetic distinctions generally aren’t binary. Things like tongue height or place of articulation are really continuous variables.) Each language has a set of phonemes— classes of phones that the speakers treat as ‘the same sound’. By convention
When you work out the sounds of your conlang, you’re creating a phonological inventory— a list of phonemes. That should be the basis of your orthography (or transliteration, if the conlang has its own writing system). Present the phonemes, then you can describe any allophonic variation. Note that the IPA can be used for either phonemic or phonetic transcriptions. Symbols can be used rather loosely for phonemes, because phonemes are really mental categories that can have different phonetic realizations anyway. Some phonemes can only be explained historically, or by reference to other dialects... we’ve already seen John Lennon realizing /t/ as [ʔ] in bottle! Your orthography doesn’t have to use IPA at all, of course! It’s helpful to readers, though, if you give the IPA in your phonology section. StressDon’t forget to give a stress rule. English has unpredictable stress, and if you don’t think about it your invented language will tend to work that way too.French (lightly) stresses the last syllable. Polish and Quechua always stress the second-to-last syllable. Latin has a more complex rule: stress the second-to-last syllable, unless both final syllables are short and aren’t separated by two consonants. If the rule is absolutely regular, you don’t need to indicate stress orthographically. If it’s irregular, however, consider explicitly indicating it, as in Spanish: corazón, porqué. In English, vowels are reduced to more indistinct or centralized forms when unstressed. This is one big reason (tho’ not the only one) that English spelling is so difficult. ToneMandarin syllables have four tones, or intonation contours: high level, rising, falling-rising, and high falling. These tones are part of the word, and can be used to distinguish words of different meanings:Tones are often described on a five-point scale, 5 being the highest. The Mandarin tones above are 55, 35, 214, and 51. Cantonese and Vietnamese have six tones. Tone is complicated by tone sandhi, where neighboring tones influence each other. For instance, Mandarin’s third tone changes to second before another third tone, so nǐhǎo ‘hello’ is pronounced níhǎo. Tones are not absolute, but relative to your normal pitch. (And if you’re wondering, songwriters may or may not try to match the tones of their lyrics to the melody.) Pitch-accentIf that seems a bit elaborate, you might consider a pitch-accent system, such as I used in another invented language, Cuêzi: the stress in a word can either be high or low in pitch. Japanese and ancient Greek are pitch-accent languages.In (standard) Japanese, syllables can be either high or low pitch; each word has a particular ‘melody’ or sequence of high and low syllables— e.g. ikebana ‘flower arrangement’ has the melody LHLL; sashimi ‘sliced raw fish’ has LHH; kokoro ‘heart’ has LHL. It rather sounds as if a tone has to be remembered for each syllable; but this turns out not to be the case. All you must learn for each word is the location of the ‘accent’, the main drop in pitch. Then you simply apply these three rules:
Thus for ike'bana we have HHHH, then HHLL, then LHLL. Phonological constraintsEvery language has a series of constraints on what possible words can occur in the language. For instance, as an English speaker you know somehow that blick and drass are possible words, though they don’t happen to exist, but vlim and mtar couldn’t possibly be English. Designing the phonological constraints in your language will go a long, long way to giving it its own distinctive flavor. Start with a distinctive syllable pattern. For instance,
Try to generalize your constraints. For instance, m + t is illegal at the beginning of a word in English. We could generalize this to [nasal] + [stop]. The rule against v + l generalizes at least to [voiced fricative] + [approximant]. (We do allow v + l in borrowings, like Vladimir.) Another process to be aware of is assimilation. Adjoining consonants tend to assimilate to the same place of articulation. That’s why Latin in- + -port = import, ad + simil- = assimil-. It’s why the plural -s sounds like z after a voiced stop, as in dogs or moms. It’s also why Larry Niven’s klomter, from The Integral Trees, rings so false. m + t (though not impossible) is difficult, since each sound occurs at a different place of articulation; both sounds are likely either to shift to the dental position (klonder) or the labial (klomper). Another possible outcome is the insertion of a phonetically intermediate sound: klompter. Alien mouthsIf you’re inventing a language for aliens, you’ll probably want to give them really different sounds (if they have speech at all, of course). The Marvel Comics solution is to throw in a bunch of apostrophes: This is Empress Nx’id’’ar’ of the planet Bla’no’no! Larry Niven just violates English phonological constraints: tnuctipun. We can do better. Think about the shape of the mouth of your aliens. Is it really long? That suggests adding a few more places of articulation. Perhaps the airstream itself works differently: perhaps they have no nose, and therefore can’t produce nasals; or they can’t stop breathing as they talk, so that all their vowels are nasal; or the airstream is at a higher velocity, producing higher-pitched sounds and perhaps more emphatic consonants. Or perhaps their anatomy allows quite odd clicks, snaps, and thuds that have become phonemes in their languages. Several writers have come up with creatures with two vocal tracts, allowing them to pronounce two sounds at once, or accompany themselves in two-part harmony. Or, how about sounds or syllables that vary in tonal color? Meanings might be distinguished by whether the voice sounds like a trombone, a violin, a trumpet, or a guitar. Suggesting additional sounds is difficult and perhaps tiresome to the reader; an alien ambience can also be created by removing entire phonetic dimensions. An alien might be unable to produced voiced sounds (so he sounts a pit like a Cherman), or, lacking lips, might skip over labials (you nust do this to de a thentrilocooist, as ooell). | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Writing systems | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
OrthographyOnce you have the sounds of your language down, you’ll want to create an orthography— that is, a standard way of representing those sounds in the Roman alphabet. I don’t recommend trying to be very creative here. For instance, you could represent a e i o u as ö é ee aw ù, with the accents reversed at the end of the word. An outlandish orthography is probably an attempt to jazz up a phonetic system that didn’t turn out to be interestingly different from English. Work on the phonemes, then find a way to spell them in a straightforward fashion. If you’re inventing a language for a fantasy world, it’s wise to take account of how English-speaking readers will mangle your beautiful words. Tolkien is the model here: he spelled Quenya as if it were Latin, didn’t introduce any really vile spellings, and kindly indicated final e’s that must be pronounced. Still, he couldn’t resist demanding that c and g always be hard (I couldn’t either, for Verdurian), which probably means that a lot of his names, like Celeborn, are commonly mispronounced. Marc Okrand, inventing Klingon, had the clever idea of using upper and lowercase letters with different phonetic values. This has the advantage of doubling the letters available without using diacritics, but it’s not very aesthetic and it sure is a tax on memory. Or you may go for neatness, as I did in inventing Verdurian. I don’t like digraphs, so I adapted Czech orthography— č for ch (tʃ), š for sh (ʃ), etc. At the time I had to create a special font, but these days you can use Unicode characters very easily. Please don’t browse the Unicode catalog as if all the characters were just decoration. As the IPA in the Kit shows, all of them have some meaning, and if you choose them for their looks it will look confusing and not too smart to anyone who knows the actual meaning. A sense of variation among the nations of your world can be achieved by using different transliteration styles for each. In my fantasy world, for instance, Verdurian Ďarcaln and Barakhinei Dhârkalen are not pronounced that much differently, but the differing orthographies give each a different feeling. Surely you’d rather visit civilized Ďarcaln than dark and brooding Dhârkalen? (Tricked you. It’s the same place.) If you’re inventing an interlanguage, of course, you shouldn’t worry about English conventions; create the most straightforward romanization you can. You’re only asking for trouble, however, if you invent new diacritic marks, as the inventor of Esperanto did. An exampleHere’s the alphabet I came up with for Verdurian: Note that there’s a one-to-one correspondence between the Verdurian alphabet and the standard English representation. This is not very naturalistic— transliteration schemes are not usually this straightforward— but it’s a good place to start. Once you can fluently read your own alphabet, feel free to add complications. A good alphabet can’t be created in a day. This one took shape over a period of weeks, as I played with various letterforms. Keep the letters looking distinct. The best alphabets spread out over the conceptual graphic space, so that letters can’t be confused for one another. Tolkien is a bad example here: the elves must have been tormented by dyslexia. If letters start to approach each other too closely, users find ways to distinguish them, in the way that computer programmers, for instance, write zeroes with a slash. Europeans write 1 with an elaborate introductory swash— impossible to confuse with I, but looking much like a 7, which has therefore acquired a horizontal slash! Remember that letters are written over and over again, over the life of an individual or a civilization. Elaborate letters are likely to be simplified. You can simulate this process by writing the letter over and over yourself; the appropriate simplifications will suggest themselves automatically. Note that I supplied upper and lower case forms, as in the Roman and Greek alphabets. The lowercase forms are all cursive simplifications of the uppercase forms (which are also the ancient forms). In retrospect I probably shouldn’t have imitated the mixed-case system, which on our world is basically limited to Western alphabets. I should have kept the ‘uppercase’ forms for ancient times, the ‘lowercase’ forms for modern times. I tried to give the letters individual histories, as with our alphabet. The letter t, for instance, derives from a picture of a cup, touresiu in Cuêzi; n was originally a picture of a foot (nega); for more see the Cuêzi grammar. I have to admit that I did this backwards— I invented pictograms that could have developed into the letters, which I had devised years before! Also note that the voiced consonants, in the uppercase forms, are simply the unvoiced forms with a bar over them (this is a bit obscured with d and t), and that the letters for š č ž are all transparent variations of each other. This slightly violates my ‘maximally distinct’ rule, but I think it adds interest to the alphabet. You’ll also notice both c and k in the alphabet. This is the sort of ethnocentrism it’s all too easy to fall into. Why would another language duplicate the convoluted history of our alphabet’s c and k? I’ve reinterpreted these symbols to refer to /k/ and /q/. DiacriticsSome advice: never use a diacritical mark without giving it a specific meaning, preferably one which it retains in all uses. I made this mistake in Verdurian: I used ö and ü as in German, but ë somewhat as in Russian (indicating palatalization of the previous consonant), and ä as a mere doubling of a. I was smarter by the time I got to Cuêzi: the circumflex consistently indicates a low-pitch accent. Avoid using apostrophes just to make words look foreign or alien. Since apostrophes are used in contradictory ways (they represent the glottal stop in Arabic or Hawai’ian, glottalization in Quechua, palatalization in Russian, aspiration or a syllable boundary in Chinese, and omitted sounds in English, French, and Italian), they end up suggesting nothing at all to the reader. Fancier writing systemsWhat, you say you want to build a syllabary? A cursive form of your alphabet? A logographic system? Read a good book on how writing systems work. Writing Systems by Geoffrey Sampson is a very good book. If that seems too much, read up on the type of writing system you want to imitate: Chinese characters, the Japanese or Maya syllabary, the Sanskrit syllabic alphabet, the Korean featural code, the all-cursive Arabic alphabet, and so on. My page on Yingzi describes a logographic script for English, as an underhanded way to explain how Chinese characters work; also see the logographic writing system for my conlang Uyseʔ. Advanced Language Construction also has a chapter on creating non-alphabetic systems. A book like Kenneth Katzer’s Languages of the World gives examples of a wide variety of scripts. Comrie’s The World’s Major Languages does the same, but gives more detail. Or invest in the 800-pound gorilla of the field, Daniels & Bright’s The World’s Writing Systems, which explains how every writing system in the world works. Logographic scripts and syllabaries tend to work best with languages that have a very limited syllabic structure— Japanese, with (C)V(n), is close to ideal; English is close to pessimal. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Word building | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
How many words do you need?Where the conlang bug bites, the Speedtalk meme is sure to follow. Let Robert Heinlein explain it: Long before, Ogden and Richards had shown that eight hundred and fifty words were sufficient vocabulary to express anything that could be expressed by “normal” human vocabularies, with the aid of a handful of special words— a hundred odd— for each special field, such as horse racing or ballistics. About the same time phoneticians had analyzed all human tongues into about a hundred-odd sounds, represented by the letters of a general phonetic alphabet. This is a tempting idea, not least because it promises to save us a good deal of work. Why invent thousands of words if a hundred will do? The unfortunate truth is that Ogden and Richards cheated. They were able to reduce the vocabulary of Basic English so much by taking advantage of idioms like make good for succeed. That may save a word, but it’s still a lexical entry that must be learned as a unit, with no help from its component pieces. Plus, the whole process was highly irregular. (Make bad doesn’t mean fail.) The Speedtalk idea may seem to receive support from such observations as that 80% of English text makes use of only the most frequent 3000 words, and 50% makes use of only 100 words. However (as linguist Henry Kučera points out), there’s an inverse relationship between frequency and information content: the most frequent words are function words (prepositions, particles, conjunctions, pronouns), which don’t contribute much to meaning (and indeed can be left out entirely, as in newspaper headlines), while the least frequent words are important content words. It doesn’t do you much good to understand 80% of the words in a sentence if the remaining 20% are the most important for understanding its meaning. The other problem is that redundancy isn’t a bug, it’s a feature. Claude Shannon showed that the information content of English text was about one bit per letter— not too high considering that for random text it’s about five bits a letter. Sounds inefficient, huh? On the other hand, we don’t actually hear every sound (or, if we’re accomplished readers, read every letter) in a word. We use the built-in redundancy of language to understand what’s said anyway. To put it another way: y cn ndrstnd Nglsh txt vn wtht th vwls, or shouted into a nor’easter, or whispered (which removes all voicing information), or over a staticky phone line. Similarly distorted Speedtalk would be impossible to understand, since entire morphemes would be missing or mistaken. Very probably the degree of redundancy of human languages is pretty precisely calibrated to the minimum level of information needed to cope with typical levels of distortion. However, go ahead and play with the Speedtalk idea. It’s good for some hours of fun, working out as minimal a set of primitives as you can; and the habit of paraphrase it gives you is very useful in creating languages. Just don’t take it too seriously; if you do, your punishment is to learn 850 words of any actual foreign language and be set down in a city of monolingual speakers of that language. Alien or a priori languagesIf you’re making up a language for a different world, you want, of course, words that don’t sound like any existing language. For this you simply need to make up words that use the sounds and the syllable structure in your language. This can fairly quickly get tiresome. I don’t advise you to sit down and come up with a hundred words at once; you’re likely to run out of inspiration, or find that all the words are starting to sound the same. You may also be creating new roots where you could more easily derive the word from existing roots. It’s not hard to write computer programs that will randomly generate words for your language (even respecting its syllable structure). If you do, remember that sounds (and syllable structures) are not equiprobably distributed in natural languages. English uses many more t’s than f’s, more f’s than z’s. (My own lexicon generator gen is available on zompist.com, and handles this for you.) Resist the temptation to give a meaning for every possible syllable. Real languages don’t work like that (unless the number of possibilities is quite low). Even if you’re working on a highly structured auxiliary language, you’ll want some maneuvering room for future expansion. And the speakers of your language shouldn’t have to throw out an old word whenever they want to construct a coinage or an abbreviation. You will want a mixture of word lengths for variety; but don’t invent too many long words. It’s better to derive long words by combining shorter words, or adding suffixes. Or, imitating the way English is full of polysyllabic borrowings from Latin and Greek, or Japanese is full of Chinese loanwords, create two languages, and build words in one out of components in the other. A few half-recognizable borrowingsYou can vary how alien your language looks to English speakers. At one extreme, the auxlang Interlingua maximizes recognizability for speakers of European languages:Esseva in le mundo scientific— specialmente le branca medical— que interlingua vermente se monstrave utile.I intended Verdurian to look mildly familiar, as if it could be a distant relative of the European languages. For example: Sul Aď e otál mudray dy tü, dalu esë, er ya cečel řo sen e sënul. To achieve this impression, I borrowed from a number of earthly languages— e.g. ailuro ‘cat’ and cuon ‘dog’ are adapted from Greek; sul ‘only’ from French; rizir ‘amuse’ and ya ‘indeed’ from Spanish; druk ‘friend’ and slušir ‘hear’ from Russian. The friendly orthography and the simple (C)(C)V(C) syllable structure also help make the language inviting. By contrast, another language, Xurnese, was intended to look more alien. There are still some cognates, but they’re more subtle. Ir nevu jadzíes mnošuac. Toš to ray do šasaup rile šizen. To am šus bunji dis kes denjic. Syu cu šus izrues šač. Another language, Old Skourene, looks even more forbidding: Nuasdi goşrimi ŋageşordor nen-ikkuḷiŋ. Languages based on existing languagesAuxlangs are often based on existing languages; for instance, Esperanto is chiefly based on French, Italian, German, and English. Here the problem of creating words largely reduces to one of acquiring enough good dictionaries. A few language creators have tried to approach the task systematically— e.g. Interlingua is based on nine languages, and usually adopts the word found in the most languages. Lojban uses a wider variety of languages, including some non-Western ones, and uses a statistical algorithm to produce an intermediate form. The intention is to provide some mnemonic assistance to a very wide variety of speakers. It’s an intriguing idea, although the execution is so subtle that the language is often mistaken for a priori. Some conlangs, including some quite sophisticated ones, aim to duplicate the feel of a particular language, or language family. These are particularly suited to alternate histories, or to fantasy countries set on Earth. Sound symbolismSome linguists claim to have found some common meaning patterns among human languages. For instance, front vowels (i, e) are said to suggest smallness, softness, or high pitch; low and back vowels (a, u, o) to suggest largeness, loudness, or low pitch. Compare itty-bitty, whisper, tinkle, twitter, beep, screech, chirp, with humongous, shout, gong, clatter, crash, bam, growl, rumble; or Spanish mujercita ‘little woman’ with mujerona ‘big woman’. Cecil Adams took advantage of this pattern when he commented, on the subject of penis enlargement surgery, that “if nature has equipped you with a ding rather than a dong, you’ll just have to live with it.” Exceptions aren’t hard to find, of course— notably small and big. Inventing alien languages, authors also simply make use of what we might call phonetic stereotypes. Tolkien’s Orkish, for instance, makes heavy use of guttural sounds and is full of consonants, while his Elvish tongues are more vocalic, and seem to have plenty of pleasant-sounding l’s and r’s. It’s curious how much mere voicing makes Orkish sound nasty to English speakers. Compare Tolkien’s Gorbag, Shagrat, Lagduf, Muzgash with unvoiced Corpac, Shacrat, Lactuf, Muscash. Derivational morphologyYou can multiply the usefulness of your basic roots, and make your langauge more consistent, by creating a system of derivations. Some of the most useful:You can just add a suffix or prefix, or you can use compounds (‘book-place’), or more exotic methods like reduplication (e.g. Malay balik ‘go back’ → balik-balik ‘go back and forth’). For more examples see any of my conlangs. These processes are very useful even if you want nothing more than a naming language. Some guidelines for not reinventing the English vocabulary
|

Back to Outline |

On to Grammar |
|